

How to do Problem Definition for a Machine Learning Project ?
The difference between a failed ML Project and a successful ML Project

C# developer | Deep Learning | Immersive Tech
Also a problem solving human, who always try to find solutions by building softwares. I am not a coder, but a creator. Coding is just my tool of choice to build or problem solving softwares.
After my last blog on Machine Learning Workflow, I was going through many articles regarding Data science and Machine Learning, and surprisingly I came across with a common and scariest thing which says, 85% of Machine Learning Model/Projects fail and only 10-15% projects are deployed for production use. (I'll drop some links to those articles in Worth a Read section of this blog)
It made to re-think to follow this path but also on the other hand we have tech giants like Tesla, Google, Amazon etc, which created all hype for AI and Machine Learning. They won't be investing billions of dollars and time if the technology is not helping them to grow or scale their businesses.
Then what's stopping us to increase the % of successful AI / ML projects ?
Let's find out.
Introduction
As a novice in this field, when I finished my first Machine Learning project, the most overwhelming part that excited me was to decide which model should I choose, which leads me to google about models, how they work, what's the math behind them.
But you know what, Machine learning is so vast that it excites you every day, makes you learn something new every day which sometimes diverts you from the end goal. Well in my case. Yes !!
Long story short, I think one of the main reason why ML projects failed because we mainly focus on most powerful and latest algorithm, instead we must think deeply about our problem before getting started, then after apply any machine learning technique.
For the first time readers or non-machine learning practitioners, we follow a framework or basically stages for a machine learning project,
- Problem Definition
- Data Gathering
- Evaluation
- Features
- Modelling
- Experiments
So, this blog is focused on most underrated stage of machine learning framework i.e Problem Definition. For more about the workflow, refer this blog.
What is the Problem ?
Let's define first, what is the meaning of a problem.

I think it's really simple, as dictionary says, a proposition in mathematics or physics stating something to be done. Something needs to be done, we don't know yet, we need to figure out, but we know some actions we need to perform.
In machine learning project, we define problems or an action item in various languages, it depends whom we're addressing to.
Languages here means the representation of same statements in different ways.
Problem definition in a proper way help us to decide our action items.
So there could be multiple representation/interpretation of same statements, but most common are,
Informal
The more simpler, The more easier to understand
I'll take one of the example of Kaggle Competitions that I recently did, Dog Breed Identification, its subtitle described the problem informally, and very easier to understand that you can even explain it to your grandma.
"Determine the breed of a dog in an image"
Or
"When I'm travelling somewhere outside in any part of the country, and I see different dogs take pictures of them, I want to know the breed of the dog."
This could be a warmup to start your Machine Learning project and very easier to explain your project to others about it's core functionality.
Formal
Be specific about your actions
For example,
we already have a trained model, and we want to increase the efficiency or tune that pre-trained model to produce better results.
Let's consider the same Kaggle Competition from the above about Dog Breed Identification problem, this is a Multi-Class classification problem and according to the Evaluation section of the competition, evaluations are done on Multi Class Log Loss between the predicted probability and the observed target.
I submitted my first results which has the Multi Class Log Loss score as $0.89909$, and my next action is to lower that score, so my problem definition would be.
"Design a machine learning model which has the Multi Class Log Loss score lower than 0.89909 by using given image samples of multiple dog breeds."
This kind of problem statements focuses on the technical aspects of the ML project, like which kind of problem it is, Multi-class Classification Problem, metrics involved Multi Class Log Loss, which should be lower than $0.89909$.
Adding these type of problem statements into project docs or readMe files is a good practice for professional Machine Learning practitioners.
Presumption
The more assumptions, The more way of conducting Experiments
While defining the problem statements, writing the list of assumptions along will also help to visualise what's available, what's not, which features or factors is very dominant while building a model.
This step will question you about the problem and the data available to fix that problem.
It can also be useful when verifying your end results while testing against the test data suppose, you're building a Heart Disease Classification model, and there are lots of feature label available like Age, Sex, Cholesterol level, Heart Rate.
But not being a Subject Market Expert of that field, we might need to build our model with lots of assumptions that which feature matters more, which is useless, so these things will be helpful while experimenting and may be we can come out with something new.
Alike or Similar
Look for examples
Looking for similar problems can help to set the target of our model, and might also be helpful if there is already a model exists which we can use it for transfer learning for our model.
We can also identify roadblocks prior to building our own model if that similar problem faced before, or may be we can use different approach and then compare results.
Is our Problem is a Machine Learning problem ?
Machine Learning technique require lots of computation power and research time to analyse the data, transform and preprocess data if we don't have enough data and then train that model with tons of samples.
So opting Machine learning in order to solve a problem is very time consuming and expensive. We have to be think very deeply about why we want to solve this problem by applying machine learning technique and can't be solved by other techniques.
Although there are many ways to identify whether our problem needs a machine learning technique or not, but that's totally dependent on the resource available because we would also want to know that if our problem will fit to any of the Machine Learning model available.
Suppose if we have structured data, then we can follow scikit-learn documentation for choosing the right estimator chart
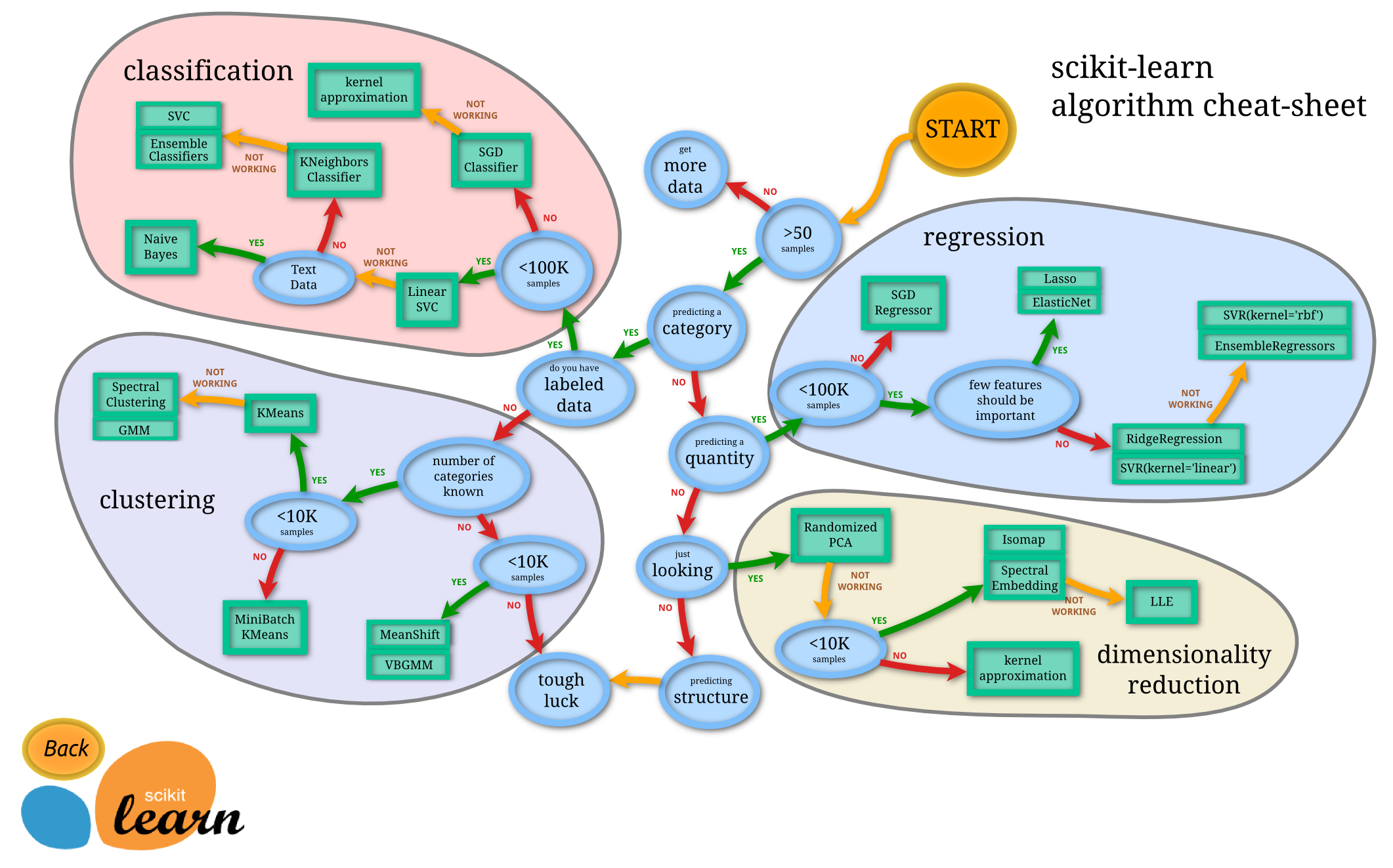
*Image is functional, please check the original link.
In scikit-learn algorithm cheat-sheet, following along the flow chart, suppose we have below 50 samples then we can't use any of the algorithm, we need to get more data.
If we have above 50 samples, then what's the requirement, whether need to predict a category or predict a quantity. Likewise this cheat-sheet would help you out whether our problem can fit any of the available machine learning technique.
Why we are solving the Problem ?
This section will help you to estimate your efforts and devotion to solve the problem, because if you have the why, then it will always push you to the right direction no matter how complex, how much time it will take to solve it but it won't let you to stop in the middle of the way.
Few key terms that might help you to create a mindset for a machine learning projects,
- Motivation
What you'll gain after solving the problem ?
For example, if we want to solve that problem for learning purpose, or for doing exercise or exploring different models then we might not bother about the metrics, like whatever will be the accuracy of identifying a correct dog breed in our Dog Breed Prediction problem, we are just building it for fun and learn. In this case we only focus on trying different models.
And suppose, if we want to solve a problem for production use, then we want to focus on the metrics and it matters for us.
- Use Case
In most of the cases, the end user is very critical for example, if your model is helpful in medical purposed then we might need to take it very seriously and our results must be very accurate. For example Health Disease Identification problem.
This require a godly mindset to achieve greater results but not impossible. Many have achieved already.
- Perks
This can also be considered as the Motivation but this may vary person to person, if you're building a model to impress your manager to get a promotion, then you might want to focus on it's documentations and representation as well.
Or you may be want to sell it to client directly, then you would be more focused on end results and the requirement of the client.
How we can solve the Problem ?
So the last thing, when defining a problem would be how we can approach the problem and solve it.
We have to list out all the steps that we are going to follow from processing the data to training and testing model.
Like,
- What type of data we have
- Is our data need to preprocess
- What features or patterns we found in our data
- What will be the target label and the format
- What model/estimator we will choose
- What are the metrics we will focus on for the evaluation of the model
Documenting the above points along with the problem definition will create an outline of the project and somewhat looks like a To-Do-List as well.
Final Thoughts
Above are some basic points which should be taken care of while defining a problem to be very clear in the beginning of project. If Problem definitions are properly exercised, it shows how well versed we are about the problem and how much planning we did before spending our time and efforts for that problem.
This is not the only reason why ML projects fail, but plays a major role in making a ML project successful.




