

Machine Learning Workflow

C# developer | Deep Learning | Immersive Tech
Also a problem solving human, who always try to find solutions by building softwares. I am not a coder, but a creator. Coding is just my tool of choice to build or problem solving softwares.
Introduction
Currently, we might be overwhelmed by tons of developments and tools available in the market to train models, to create algorithms from scratch or whether to find insights from the data using different tools. Irrespective of these things, every Machine Learning or Data Science project follow a proven path to achieve the end goal. That path contains some phases which can be defined as Machine Learning Workflow.
This can also be defined as ML Framework or Operations Workflow
From several decades we have been collecting data through various modes and dumping them into the web, most commonly through mobile apps, websites, IoT devices etc which results into enormous collection of data, some may say meaningful story about them(data) and some may not. To identify which data tells us a meaningful story and can be considered for further experiments, researchers and analysts use various techniques and that process is called Data Collection.
After collecting the data, we want to find out what that data can predict, what information it can produce and how it can be used to train a machine or computer. These things are done in the process called Data Modelling. In this process we analyse the data, perform experiments with data, use algorithm and produce desired outcomes. To achieve efficient results based on that data we use that ML Workflow or Framework.
So let's see what are the suggested phases in the workflow for efficient results.
Phases in ML Workflow
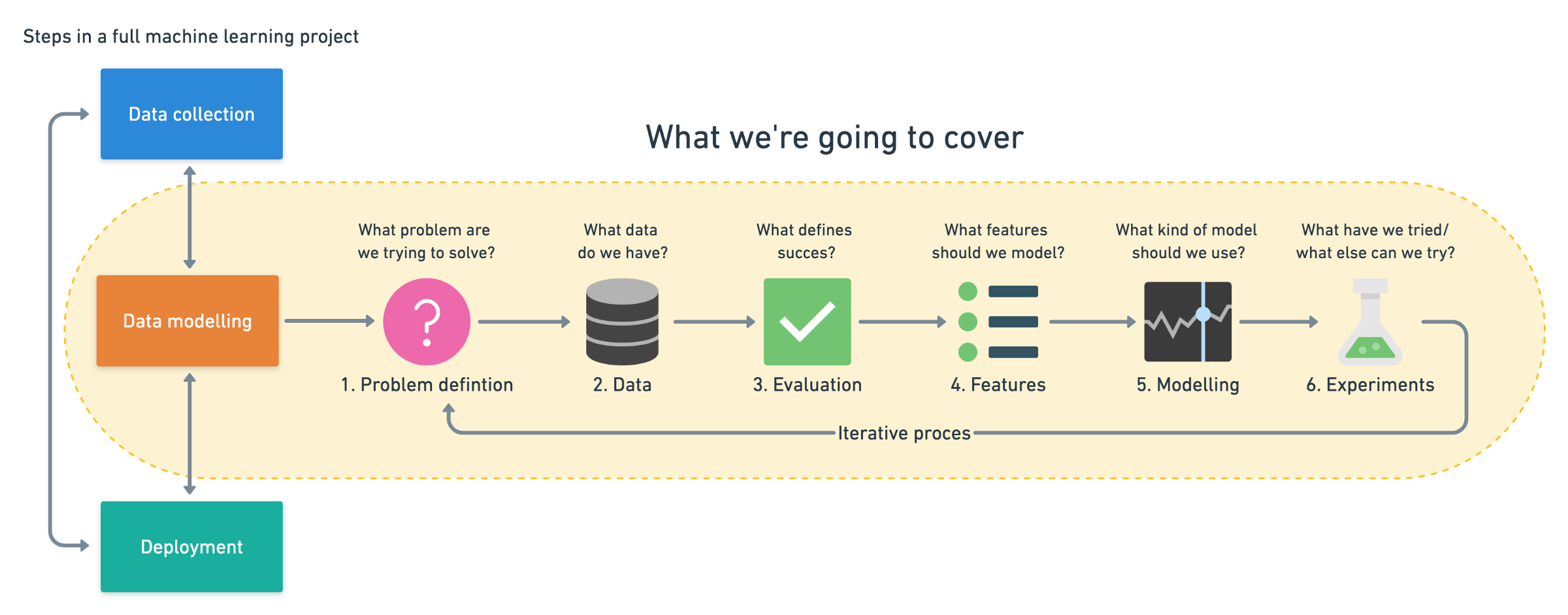
Problem Definition
This phase will focus on the problem we trying to solve through Machine Learning and most important, this phase will also tell whether our problem needs to be solved through Machine Learning program or not.
We can identify the problem by differentiating the problem into the types of Machine Learning such as Supervised, Unsupervised, Reinforcement and Transfer Learning. It means we need to phrase our problem in such a way so that it should tell whether our problem can be solved by Supervised learning, or Unsupervised or other types. It can even tell detailed information regarding the type of problem, is it a Classification problem, or a Regression problem or a Recommendation problem.
You can read the definitions of them on this blog.
Data
Now, we have identified what is the problem exactly, the next thing is to know what type of ingredients or technically what type of data we have to solve that problem.
Assuming, we already have good amount of data with us, then it must be in one of the two forms. Structured or Unstructured.
Structured, in form of tables (row and columns), an Excel spreadsheet. Unstructured, in form of images, audio files, random texts.
Under these two forms, each would have either Static data which is unlikely to change in the future or Streaming data which is likely to change constantly even after the model creation or project deployed on the server. But there are no set rules, that you can't have both types of data in your single data set. In some cases, there would be both. We would need to understand the type of data and also we need to find a relation with problem definition.
Evaluation
Next, we need to determine what is our moment of success of building a Machine Learning project. We've our problem definition and our data with us, now we want to decide what are our parameters to evaluate the results.
Thinking about the results might distract you along the process, but having a sight of the end goal will keep you on right track.
So to identify the evaluation metrics, problem definition plays a crucial role here, as it depends on the type of problem we are trying to solve.
For example, if this is a classification problem, then we have to evaluate the results with the percentage of Accuracy. Suppose, we want to classify the animal into two types, dog or cat. So in this case, we want how accurate the model is performing to identify the animal correctly.
If the problem is Recommendation problem, then we will use different evaluation metrics.
Features
In this phase, again data will be exercised in a more serious way. Simply, when we talk about features as in general, it means the characteristics of that product or an item.
Suppose, What are the features of an animal ? It has legs, how many legs, it can walk, it barks or meows, sex of the animal.
We need to identify what features does our data have and after that most importantly which features creates a meaningful sense to be used to build our model. Since we have different types of data structured and unstructured, and different forms of data within those type of data are called features.
For example we are trying to solve a supervised learning problem with having structured data, so the data of an animal can look like below,
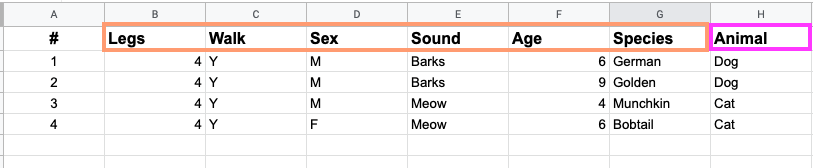
So here, the columns inside a skin color rectangle are called Feature variables and the pink rectangle is our expected outcome, i.e called Target variables.
Feature variables are used to determine target variables.
Inside feature variables we can further classify this into three types as Categorical, Continuous(numerical) and Derived features.
Categorical features like Yes/No, Male/Female. Numerical features like Age, Height, Weight etc. Someone can also derive new features from different features of the given data and create a new/alter existing one is called Derived feature and that process is called feature engineering.
Modelling
This is where Machine learning techniques comes into play. All the types of existing models, tools and techniques are used here to build a good performing model for our problem.
Based on our problem and data, we need to choose which model we want to use.
Before that, the most important thing in machine learning process is to split the data we have into 3 sets before building our model. This is also known as 3 set rule.
The data should be divided into training set, validation set and test set.
- Training Set, 70-80% of data, we'll train our model using this data.
- Validation Set, 10-15% of data, this data will be used to validate and tune our model.
- Test Set, 10-15% of data, we will test and compare our model using this.
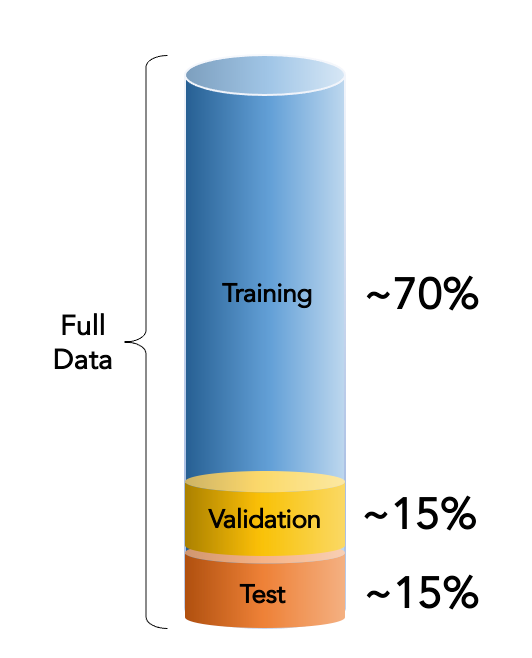
This is very important practice to bring efficient result from our model because if we use same data in every step then machine will start memorising it and produces fake results, it won't learn.
Back to Modelling, there are three steps/parts for modelling,
Choosing and Training a model

Based on the data and the problem we choose our model.
For example,
if we have structured data, we can choose available models like CatBoost, XGBoost, RandomForest.
if we have unstructured data, we might use Deep Learning or Neural Network and Transfer Learning for model training.
After choosing a model, we train it using the training data.
Tuning a model

In this process, we will try to improve the performance of the model by adjusting the parameters of the model. Depending on the model we use, hyper parameters of each model will be different.
For example,
if we're using RandomForest - we adjust number of trees.
In case of Neural Network - we adjust the number of layers.
These tuning will be done on Validation data set.
Model Comparison

We want to see how our model will perform in real world, so we'll try to test our model with fresh data that are in Test set and also compare the metrics (that we decided in Evaluation step) produced during tests while trying with different models.
While comparing the models, we should use the same data set and based on the requirement, compare the produced analytics like accuracy, training time and prediction time.
It should be like,
- Model 1, trained on data X, evaluated on data Y.
- Model 2, trained on data X, evaluated on data Y.
Experiments
This phase will be the repeat process of all other steps that we did earlier. Just how effortless human baby learn while seeing a dog multiple times like in a garden, in a TV or in a picture, machine also learns by multiple iterations and variations.
We do experiments to get the best possible outcome trying different approaches, models and data sets.
Performance measurement on each experiments differ according to the parameters we decide for evaluation. But our goal is to approximately match the performance of the model during training and testing after that when it's ready for the deployment we also need to consider how it'll perform in real world scenario because it happens some models perform better in development environment but fail in production.
Final Thoughts
Above steps can be applicable for most machine learning projects, but based on the requirement we can add more layers into each step or we can add extra step its totally individual choice of action but these are some basic fundamentals which every machine learning problem follows.
I've tried to cover these steps in a very brief way, if you want to explore more in detail you can check Daniel Bourke's blog and also some of the terms like models name may sound unfamiliar now but I'll cover those with experiments in coming blogs.
Til then,
Keep Building Yourself🦾




