



Photo by Alan Rodriguez on Unsplash
Fine Tune neural network models using TensorFlow
Quick step guide to fine-tune tensorflow hub models for your own use-case


What is Fine-Tuning
According to wikipedia 😅,
"fine-tuning is the process in which parameters of a model must be adjusted very precisely to fit with certain observations."
I'm not sure if the above two lines were able to define fine-tuning properly, so let's try to understand in layman,
As we're already living in the AI age, we have an abundance of open-sourced pre-trained models available which may be trained for every use case. Each day the community is growing and creating fine-tuned versions of pre-trained models leveraging the power of transfer learning for various use cases.
If you want to get familiar with Transfer Learning and its implementation. Please read this blog first.
So, fine-tuning is another type of transfer learning method where the pre-trained model weights from another model are unfrozen and tweaked during training to better suit our data.
This process can only be done after we feature extracted the model, then we can unfreeze some of the layers of that model which we want to train and adjust their weights.
Fine-Tuning Vs Feature Extraction
For feature extraction transfer learning, we can only train the top 1-3 layers like the input layer of the pre-trained model, and the output layers, but in fine-tuning transfer learning, we might be able to train 1-3+ layers of a pre-trained model.
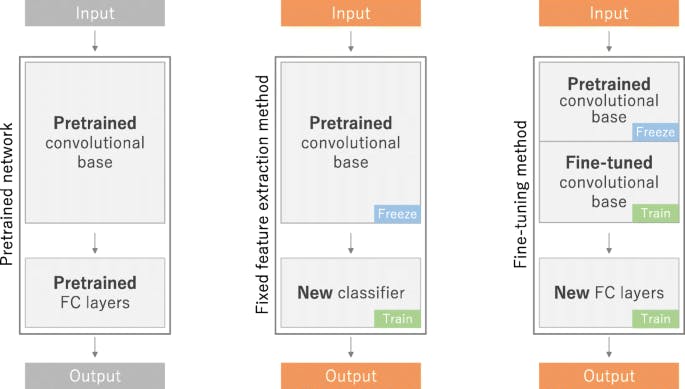
In the above image, all the architectures are examples of convolutional neural networks, suppose we want to use it for our image classification problem.
The centre architecture is a feature-extracted model, in which the Input and Output layers are unfrozen and the pre-trained convolutional base model is frozen which means it's not trainable, we can only use the weights or patterns that are learned by the model on their data for our dataset. And for this type of transfer learning, we only need less amount of data to fit into the feature-extracted model, as the base model's layers will be frozen.
# Feature extraction ResNetV250
import tensorflow as tf
base_model = tf.keras.applications.ResNet50V2(include_top=False)
# include_top = False, so that we can add our own output layers
base_model.trainable = False
# trainable = False, as the layers will be frozen and weights
# will be unchanged
The right-most architecture is a fine-tuning method of transfer learning, this step comes after feature extraction of any pre-trained model and also when we are not satisfied with the results of the feature-extracted model's predictions, then we can try fine-tuning that model and let it learn patterns or adjust weights on our dataset.
For this approach, we need more data to fit into the model as compared to the feature-extraction method.
Steps to Fine-Tune
There are some steps to fine-tune a neural network model which are listed below, for this blog considers a convolutional neural network architecture model from tensorflow_hub but the approach can be applied to any open-sourced models.
If you know how to feature extract a model, then directly jump to Step 5.
Create the
base_modelusingtf.keras.applications()Pass
include_top = Falseand initially make all the layers ofbase_model.trainable = FalseDesign the rest of the neural network architecture between
inputsandoutputsCompile the model. Until this step, we covered how to feature extract a model
For fine-tuning, first, we need to make all the layers of
base_model.trainable=True. This will unfreeze all the layers.Now, refreeze the layers which we do not want to train or adjust the weights/pattern learned on the original dataset.
After doing changes on
base_model, we have to re-compile the model.Great! Now the model is fine-tuned and ready to be trained for our custom dataset.
Let's see the complete implementation,
import tensorflow as tf
input_shape = 'your_input_shape' # the shape of input on which
# pretrained model is trained on
number_of_neurons = 'number of classes' # since this is an image classification problem so basically it would be the number of classes our model is predicting on will be equal to number of neurons
# 1. Create the base_model and pass include_top = False
base_model = tf.keras.applications.ResNet50V2(include_top=False)
# 2. Freeze all the layers
base_model.trainable = False
# 3. Design the network
inputs = tf.keras.layers.Input(shape=input_shape, name='input_layer')
x = base_model(x, training=False) # inference mode
x = tf.keras.layers.GlobalAveragePooling2D(name='global_average_pooling_layer')(x) # extracting only the important feature of base_model
outputs = tf.keras.layers.Output(number_of_neurons, name='output_layer', activation='softmax')(x) # softmax for multiclass
model = tf.keras.Model(inputs, outputs)
# 4. Compile the model
model.compile(loss='loss_functions_problem_based', # it could be binary_crossentropy or categorical_crossentropy
optimizer='your_favourite_optimizer', # Adam/SGD or any
metrics=['accuracy'])
# Fit the model first, if we get the desired results then no need to fine-tune further,
model.fit(train_data,epochs=5,validation_data=test_data)
# 5. unfreeze the layers
base_model.trainable = True
# 6. Let's say we want to train top 5 layers of base_model, so we will freeze all the layers except last 5
for layer in base_model.layers[:-5]:
layer.trainable=False
# 7. Recompile the model
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
metrics=['accuracy'])
# 8. Fit the model
model.fit(...)
By now our model will show results based on the patterns learned or weights adjusted after fine-tuning.
If we're satisfied with the results, then we can move forward with further experimentation, or if not then we can repeat Step 6, unfreeze more layers and observe the results.
Few Things to Note:
Fine-Tuning won't always give assurance in the increase of the model's performance. It's subject to use cases.
Fine-Tuning may require effort in collecting more data and work on the preprocessing of data. If you have a good source to collect data then you're in luck.
Sometimes fine-tuning might result in overfitting.
In
Step 7, I've usedAdamas the optimizer function (you can use any) and reduced its defaultlearning_ratefrom0.001to.0001, because I want to make sure that the updates to the previously trained weights aren't too large.
We've just seen one approach to fine-tuning a model, there are several approaches based on the problem you are trying to solve, and the pre-trained model and its configuration of layers.
I'll be introducing some more approaches in the coming blogs.
Till Then, Keep learning && building. 🦾